new stata 17
More
이제 정식으로 새로운 버전 17이 출시되었습니다.
우리는 이제 Stata 17의 여러가지 새로운 기능을 소개하고자 합니다.
아래에 29가지의 주요 기능을 소개하는 목록을 작성했습니다.
새 버전에서 주목할 만한 새로운 기능
New Stata 17
FAST
ACCURATE
EASY
- 1. 새로워진 표 기능
- 2. 베이지안 계량경제학
- 3. Stata 속도향상
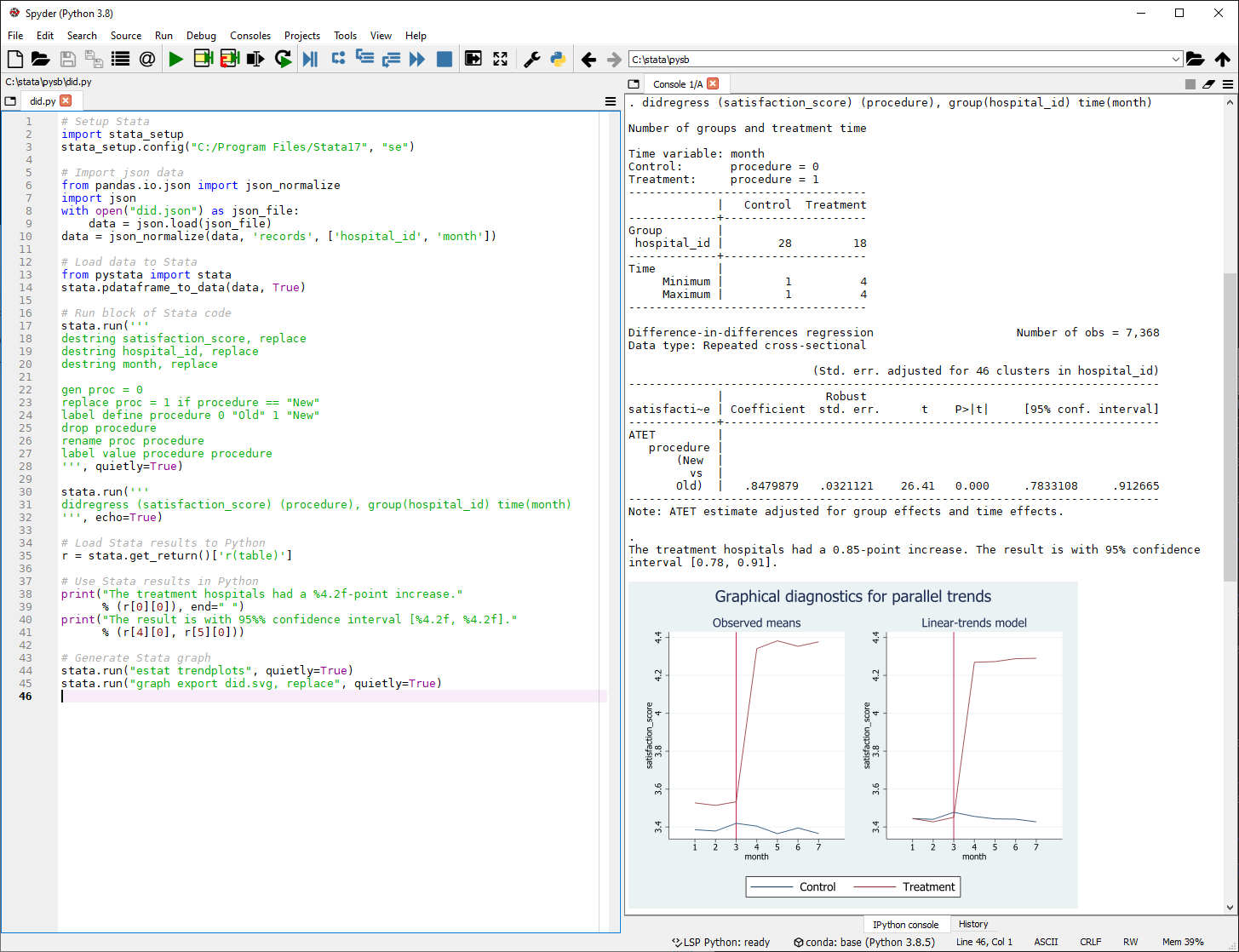
- 4. 이중차분, 삼중차분 모형
- 5. 구간-중도절단 Cox 모형
- 6. 다변량 메타분석
- 7. 베이지안 VAR 모형
- 8. 베이지안 다층모형 - 비선형, 결합모형, SEM 형태 등
- 9. 처치효과 라쏘 추정
- 10. Galbraith 그래프
- 11. Leave-one-out 메타분석
- 12. 베이지안 종단/패널자료 모형
- 13. 패널 다항로짓 모형
- 14. 영과잉 서열로짓 모형
- 15. 비모수 추세 검정
- 16. 베이지안 동적예측
- 17. 베이지안 IRF, FEVD 분석
- 18. 라쏘 패널티 모수선택을 위한 BIC 제공
- 19. 군집화 자료를 위한 라쏘
- 20. 베이지안 선형/비선형 DSGE 모형
- 21. Do-파일편집기 - 강화된 탐색 및 북마크
- 22. 새로운 날짜 및 시간함수
- 23. Intel Math Kernel Library 지원
- 24. 애플 Silicon 탑재 맥 지원
- 25. JDBC 지원
- 26. 자바 통합환경 지원
- 27. H2O 통합환경 지원
- 28. Python 내 Stata 통합
- 29. Jupyter Notebook 내 Stata지원
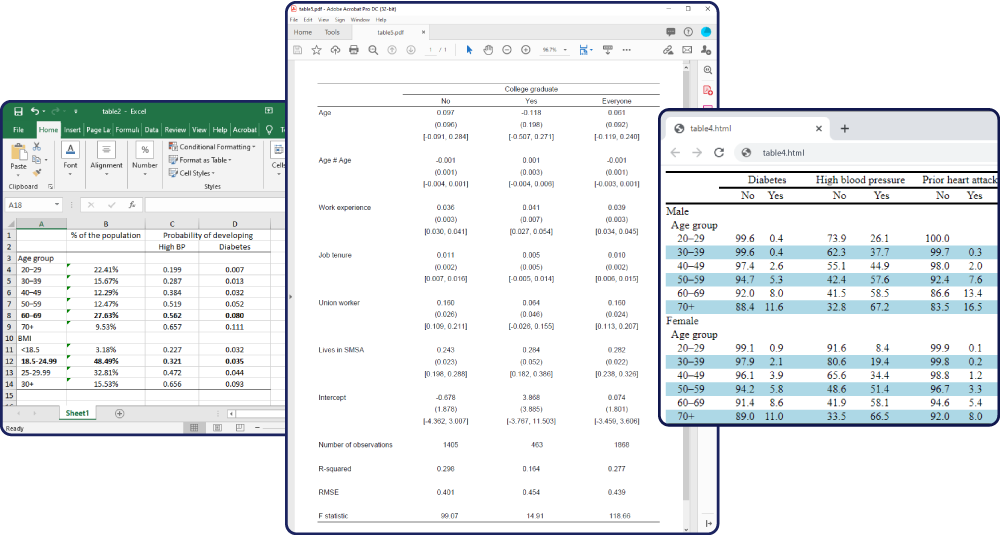
사용자는 이제 회귀모형의 결과비교, 기초 통계량과 같은 표를 쉽게 작성할 수 있으며, 사용자 서식을 생성할 수도 있고, 그 서식을 표에도 적용할 수 있습니다. 그리고 MS워드, PDF, HTML, LaTeX, MS 엑셀 및 Markdown으로 표를 내보내거나 문서에 포함시킬 수 있습니다. 이러한 기능은 새로워진 table 명령어에서 제공합니다. 그리고 새롭게 추가된 collect 접두명령어는 사용자가 실행한 명령어와 결과를 수집하고 다양한 형식으로 내보낼 수 있습니다. 사용자는 또한 새로운 Tables 빌더를 통해 마우스 클릭으로 쉽게 표를 생성할 수 있습니다.
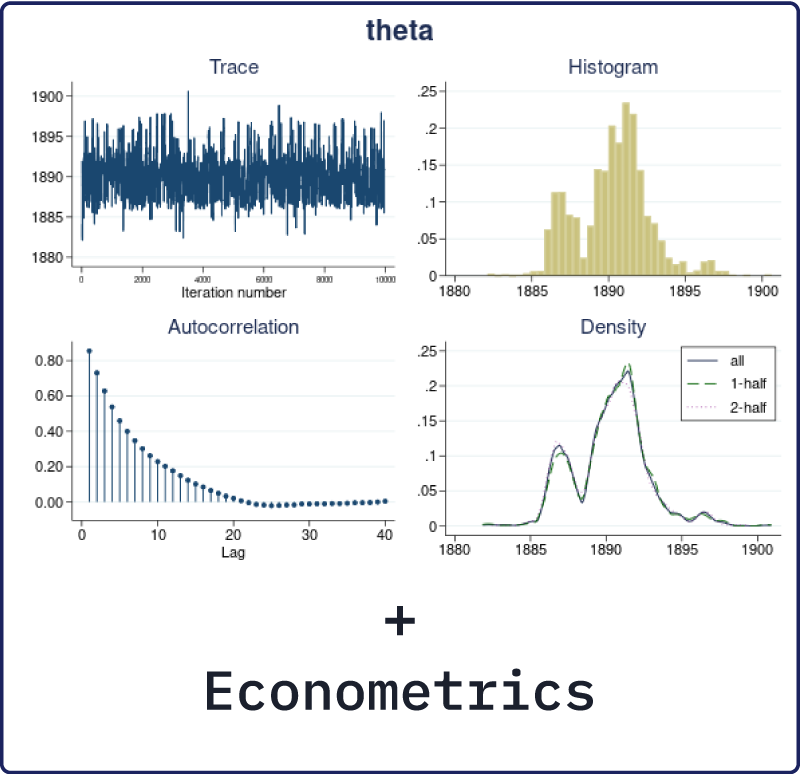
Stata는 이전 버전에서 계량경제학 모형 뿐만 아니라 베이지안 통계도 지원했습니다. Stata 17에서는 두가지 기능을 통합하여 베이지안 계량경제학 모형을 제공합니다. 경제학적 과정에 대한 질문에 답하기 위해 확률적인 표현이 필요한 경우가 있습니다. 예를 들면, 직업훈련에 참가한 사람이 향후 5년동안 고용된 상태로 있을 가능성이 더 높은가? Stata의 새로운 베이지안 계량경제학 기능은 이러한 질문에 도움을 줍니다. 횡단면, 패널자료, 다층 그리고 시계열 모형과 같은 많은 베이지안 모형을 추정하십시오. 그리고 베이즈 요인을 통해 모형을 비교하고 적합치를 얻고 예측을 진행하십시오. 이 밖에도 더 다양한 기능을 제공합니다. 계량경제학에서 베이지안 방법이 가진 장점 중 하나는 모수와 관련한 외부 정보를 모형에 통합시킬 수 있다는 점입니다. 이러한 정보는 과거자료나 경제학 지식으로부터 자연스럽게 얻을 수 있을 것입니다. 어느 쪽이든 베이지안 접근은 외부정보와 관찰된 데이터의 통합을 통해 경제학적 과정에 대해 더 현실적인 관점을 제공할 수 있습니다. Stata17에서 제공하는 몇몇 베이지안 계량경제학 관련기능은 아래와 같습니다. Bayesian VAR modes: 베이지안 VAR 모형 Bayesian IRF and FEVD analysis: 베이지안 IRF와 FEVD 분석 Bayesian dynamic forecasting: 베이지안 동적 예측 Bayesian longitudinal/panel-data models: 베이지안 종단/패널자료 모형 Bayesian linear and nonlinear DSGE models: 베이지안 선형/비선형 DSGE 모형
Stata는 정확도와 속도를 추구합니다. 많은 경우 정확도와 속도는 함께 추구하기 어렵습니다. 하지만 Stata는 사용자들에게 최고의 정확도와 최고의 속도를 제공하고자 노력하고 있습니다 그래서 우리는 sort 와 collapse 명령어의 알고리즘을 개선하여 속도를 향상시켰습니다. 또한 다층혼합모형 명령어인 mixed와 같은 몇가지 추정명령어의 속도를 개선하였습니다
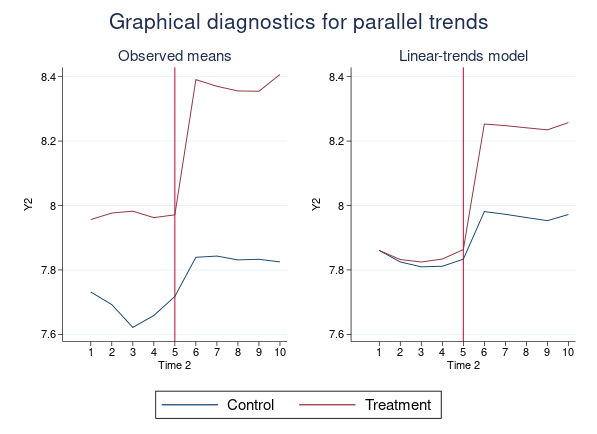
새로운 명령어인 didregress와 xtdidregress는 반복측정 자료에서 이중차분(difference-in-differences, DID)과 삼중차분(difference-in-difference-in-differences, DDD) 모형을 추정합니다. didregress는 반복측정 횡단면 자료(repeated-cross-sectional data)에 적합하고 xtdidregress는 종단/패널자료에 적절합니다. DID와 DDD 모형은 반복측정자료에서 처치그룹의 평균처치효과(ATET)를 추정하는데 사용됩니다. 처치효과는 혈압에 영향을 미치는 약의 효과나 취업에 영향을 미치는 직업훈련의 효과 등이 될 수 있습니다. 이전부터 이미 teffects 명령어를 통해 처치효과 추정을 지원하였으나 이 명령어는 횡단분석에 적합한 명령어입니다. 횡단면 분석과 다르게 DID 분석은 반복측정된 그룹 및 시간효과를 통제하여 ATET를 추정합니다. DDD 분석은 추가적으로 그룹효과 및 그룹과 시간의 상호작용 효과를 통제합니다.
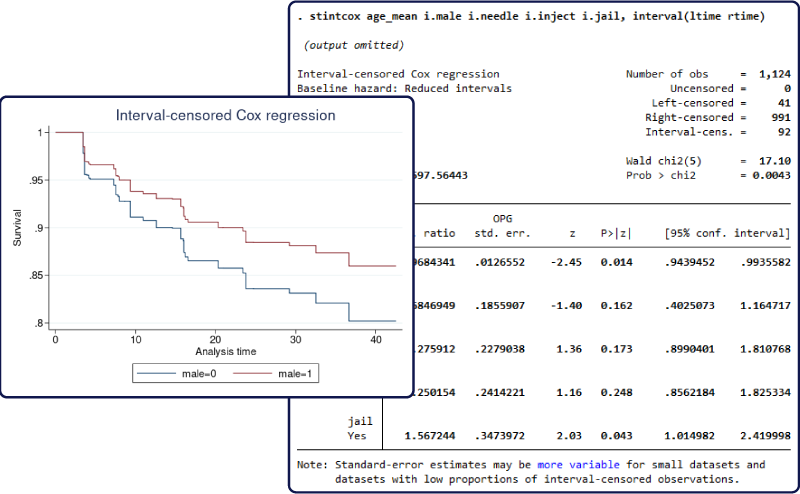
준모수 Cox 비례 위험회귀모형은 중도절단이 없거나 우측-중도절단이 있는 사건-시간자료를 분석하는데 일반적으로 활용됩니다. 새롭게 추가된 stintcox 명령어는 구간-중도절단 사건-시간 자료를 Cox모형을 기반으로 추정하는 명령어입니다. 구간-중도절단은 암의 재발과 같은 관심사건이 일어난 시간이 언제였는지 직접적으로 관찰하지 못했지만 어떤 시간구간에서 일어났는지 알고 있을 때 발생합니다. 예를 들면, 암의 재발은 주기적인 검진사이에 발견될 수 있습니다. 그러나 암이 재발한 명확한 시간은 관찰할 수 없습니다. 우리는 오직 암이 재발한 시간이 이전 검진과 현재 검진시점 사이에 있다는 것만 알 수 있습니다. 이러한 구간-중도절단이 발생한 경우 이를 무시하면 편향이 있는 잘못된 결론을 도출할 수 있습니다. 구간-중도절단자료는 사건이 정확히 언제 발생했는지 알 수 없습니다. 따라서, 준모수 추정은 기저위험함수(baseline hazard function)가 좌측으로 완전하지 않게 정의되지 않아 어려움이 있습니다. 이러한 데이터에서 기저위험함수 추정을 위한 준모수적 방법에는 spline 방법이나 piecewise-exponential 모형이 있습니다. 구간-중도절단 사건-시간자료의 진정한 준모수적 모델링은 현재의 방법론적 진전이 있기 전까지는 불가능하였지만 이제 stintcox 명령어를 통해 가능하게 되었습니다.
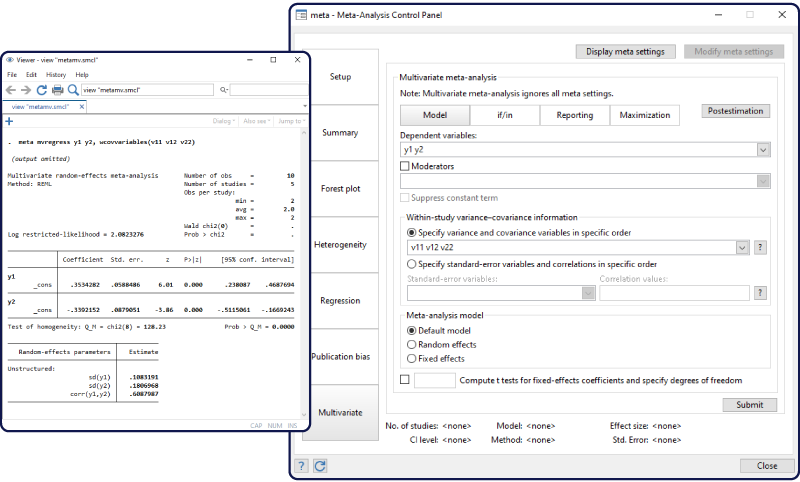
사용자는 다수의 연구들로부터 결과를 분석하기를 원합니다. 그 연구들은 연구 내에 상관이 있는 다수의 효과크기를 보고합니다. meta 명령어를 통해 수행되는 개별적인 메타분석에서는 이러한 상관을 반영할 수 없습니다. 이제 새롭게 제공하는 meta mvregress를 통해 상관을 반영하고 이를 설명하는 다변량 메타분석을 수행할 수 있습니다.
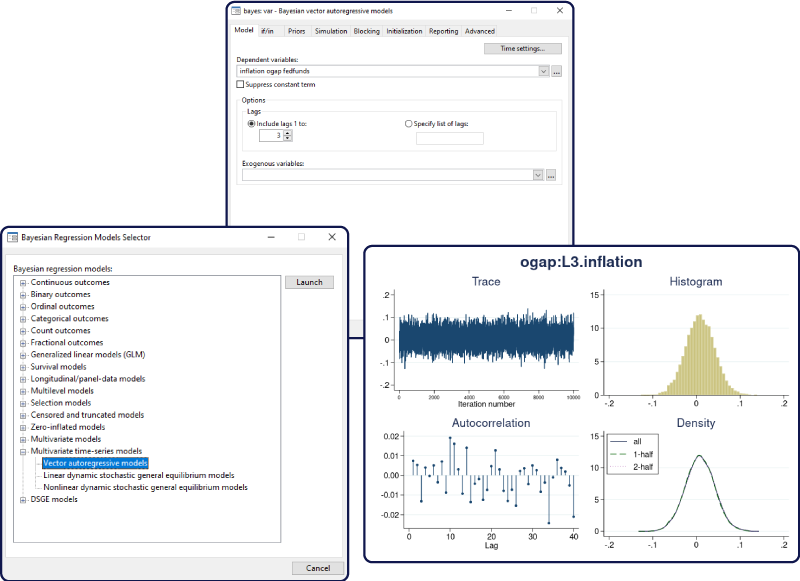
bayes 접두명령어의 var 명령어 지원을 통해 이제 베이지안 벡터자기회귀모형을 추정할 수 있습니다. VAR 모형은 예측변수로 종속변수의 시차변수를 포함하는 다중시계열 사이의 관계를 분석하는데 활용됩니다. 이러한 모형에서는 매우 많은 모수를 추정해야 하는데, K개의 종속변수와 p시차가 있는 경우에 적어도 p(K^2+\nn1)의 모수가 추정됩니다. 따라서, 자료의 크기가 작은 경우 모형의 안정적인 추정이 어렵다는 문제가 있습니다. 이러한 경우 안정적인 추정을 위해 베이지안 VAR 모형은 모수들의 사전정보를 통합하여 문제를 해결할 수 있습니다.
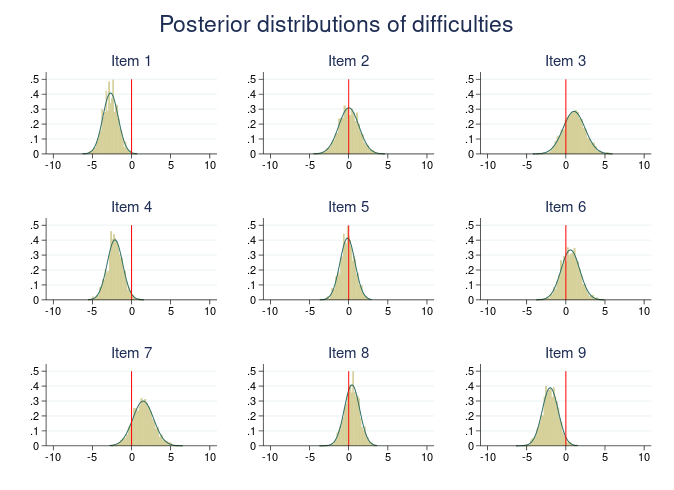
사용자는 이제 bayesmh 명령어에서 새롭게 제공하는 세련된 임의효과 구문을 통해 베이지안 다층모형을 매우 유연하면서 폭넓게 모델링 할 수 있습니다. 사용자는 일변량 선형모형과 비선형 다층모형을 더 쉽게 추정할 수 있습니다. 그리고 선형/비선형 성장모형, 비선형 다층모형, 종단 및 생존-시간 결합모형, 구조방정식 형태 모형 등과 같은 다변량 선형 및 비선형 다층모형을 바로 구성할 수 있습니다!
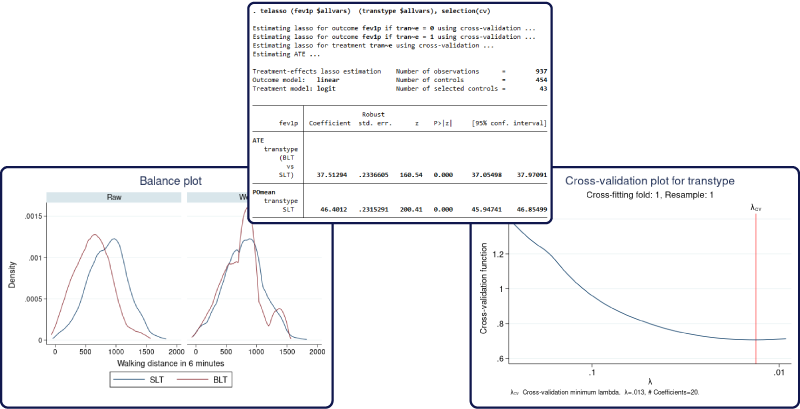
그동안 사용자는 처치효과를 추정을 위해 teffects 명령어를 사용하였습니다. 그리고 수백, 수천 혹은 그보다 더 많은 공변량의 통제를 위해 lasso 명령어를 사용하였습니다. 처치효과 추정과 많은 공변량의 통제는 개별적으로 이루어졌습니다. 그러나 이제 새롭게 제공하는 telasso 명령어를 통해 매우 많은 공변량을 통제한 상태에서 처치효과를 추정할 수 있습니다.
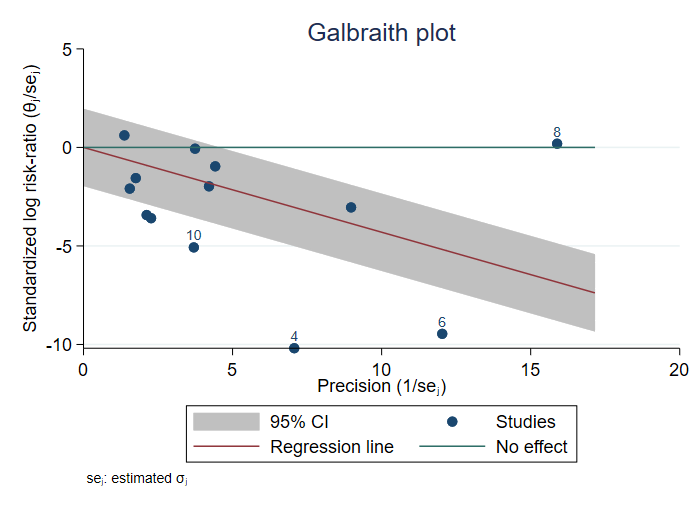
새로운 meta galbraithplot은 메타분석을 위한 Galbraith plots을 생성합니다. 이 그래프는 연구들의 이질성을 탐색하거나 잠재적인 이상치를 찾아내는데 유용합니다. 또한 메타분석을 진행할 때, 많은 연구들의 결과를 요약하기 위해 사용되었던 forest plots의 대안으로 사용할 수 있습니다.
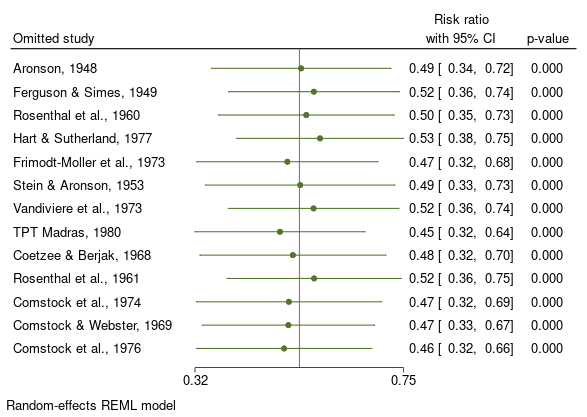
사용자는 이제 meta summarize와 meta forestplot에서 새롭게 제공하는 leaveoneout 옵션을 이용하여 leave-one-out 메타분석을 할 수 있습니다. leave-one-out 메타분석은 각각의 분석에서 한개의 연구를 제외하여 다중 메타분석을 수행합니다. 몇몇 연구들이 과장된 효과크기를 산출하게 하는 것은 일반적인 일이며, 이는 전체결과를 왜곡시킬 수 있습니다. leave-one-out 메타분석은 각각의 연구가 전체 효과크기 추정치에 미치는 영향을 평가하는데 매우 유용합니다.

사용자는 연속형 종속변수를 위한 xtreg, 이분형 종속변수를 위한 xtlogit이나 xtprobit, 서열형 종속변수를 위한 xtologit, xtoprobit 등의 명령어를 통해 패널자료 혹은 종단자료 모형을 추정합니다. Stata 17에서는 이러한 모형들의 베이지안 추정을 간단하게 bayes 접두명령어 추가하여 수행할 수 있습니다.
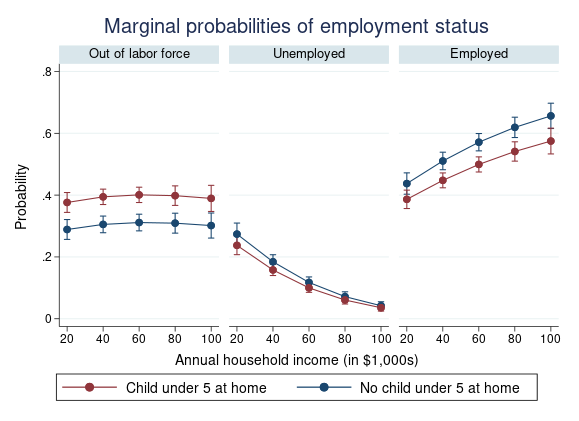
Stata의 새로운 xtmlogit 명령어는 반복측정된 범주형 종속변수를 모델링하는 패널 다항로짓 모형을 추정합니다. 우리에게 개인이 선택한 음식점을 몇 주 동안 측정한 자료가 있다고 가정해봅시다. 음식점 선택들은 서열이 있지 않은 범주형 변수입니다. 그래서 우리는 분석을 위해 이전에는 mlogit 명령어를 군집 로버스트 표준오차와 함께 사용하였습니다. 그러나 xtmlogit 명령어는 개인특성을 직접적으로 모델링하기 때문에 더 효율적인 결과를 제공합니다. 그리고 이는 공변량과 상관을 가진 개인특성에 대해 적절히 설명할 수 있습니다
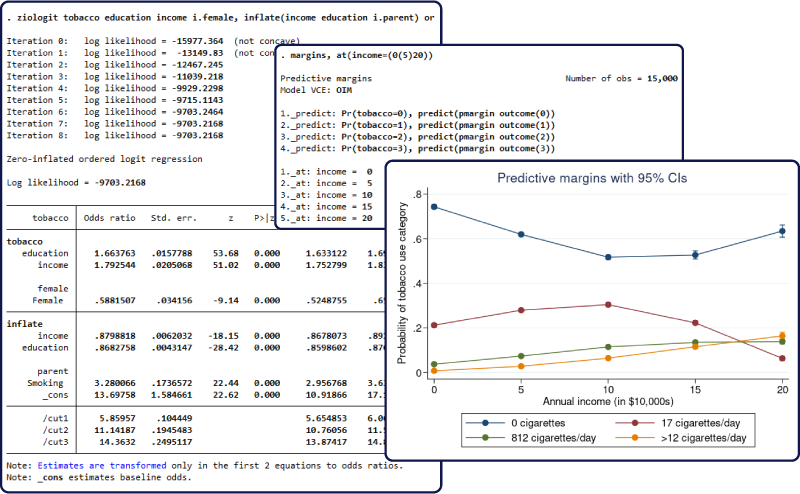
새로운 명령어 ziologit는 영과잉 서열 로지스틱 회귀모형을 추정합니다. 이 모형은 일반적인 서열 로지스틱 모형에 적합한 자료와 비교하였을 때 서열이 낮은 범주의 관측치가 매우 높은 비중을 차지하는 자료에 적합합니다. 우리는 가장 낮은 범주의 관측값을 0으로 정의합니다. 왜냐하면, 전형적으로 0은 행동이나 특성이 없음을 의미하기 때문입니다. 영과잉 모형은 로지스틱 모형과 서열로지스틱 모형 모두에서 0이 발생한다고 가정하고 이를 설명합니다. 각 모형은 각각의 공변량을 가질 수 있으며, 모형의 계수를 오즈비로 변환한 추정 결과를 출력할 수 있습니다.
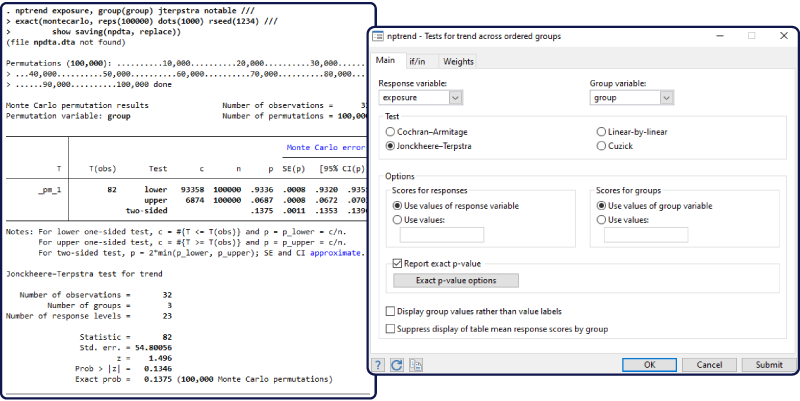
nptrend 명령어는 이제 서열이 있는 그룹들 사이의 추세 검정을 위한 4가지 방법을 지원합니다. 사용자는 Cochran–Armitage 검정, Jonckheere–Terpstra 검정, linear-by-linear 추세검정, 순위를 이용한 Cuzick 검정 중 하나를 선택할 수 있습니다. 4가지 검정방법 중 첫번째부터 세번째까지는 이번에 새롭게 추가되었고 네번째 검정은 이미 nptrend에서 지원하고 있습니다.
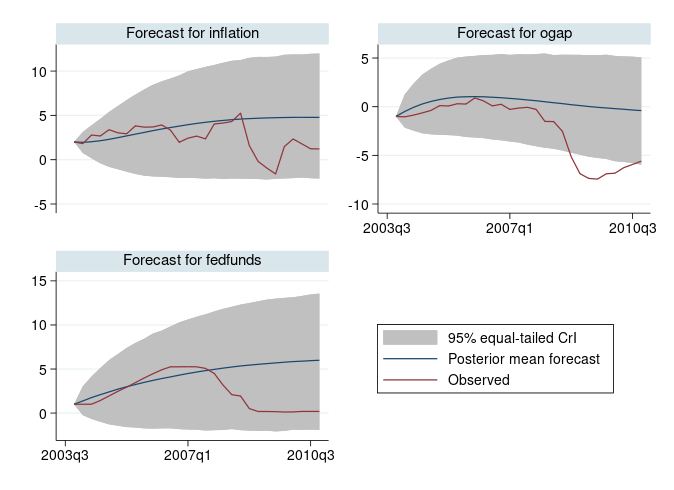
동적예측은 벡터자기회귀(VAR) 모형과 같은 다변량 시계열모형을 추정한 후 공통적으로 사용하는 예측과정입니다. 사용자는 전통적인 var 모형을 추정한 이후에 fcast 명령어를 사용하여 동적 예측을 진행할 수 있습니다. Stata 17부터는 새롭게 추가된 bayes: var 명령어를 통해 베이지안 VAR 모형을 추정하고 bayesfcast 명령어를 사용하여 베이지안 동적 예측을 진행할 수 있습니다. 베이지안 동적예측은 단일 예측치를 생성하는 전통적 분석과 달리 예측값의 전체 시계열을 생성합니다. 이러한 생성된 전체 시계열은 모델링과 관련한 다양한 질문과 그에 대한 답을 얻는데 활용될 수 있습니다. 예를 들어, 예측의 불확실성 추정시 모형이 점근적 정규성 가정없이 미래의 관측치를 얼마나 잘 예측하는지 평가할 수 있습니다. 이는 특히 점근적 정규성 가정이 쉽지 않은 소규모 시계열 자료에서 매우 유용합니다.
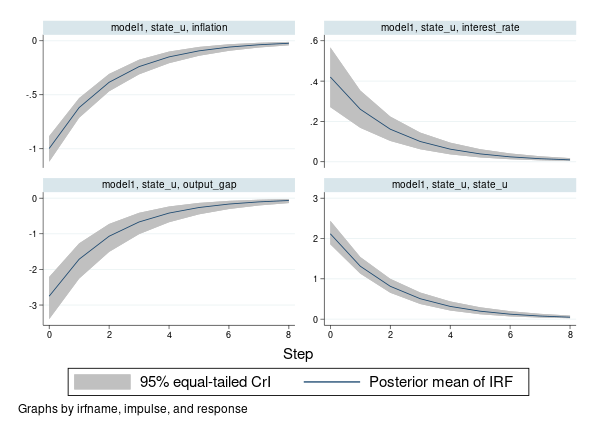
충격-반응 함수(IRF), 동적-승수함수, 예측-오차 분산분해(FEVD)는 VAR 모형과 같은 다변량 시계열 모형 결과를 설명하는데 주로 사용됩니다. VAR모형은 해석하기 어려운 많은 모수를 가지고 있습니다. IRF와 다른 함수들은 다수의 모수효과를 통합하여 기간마다 하나의 요약 결과로 제시합니다. 예를 들어, IRF는 특정변수에서 충격이 발생할 때 주어진 종속변수에 미치는 효과를 측정합니다. 베이지안 IRF와 다른 관련함수들은 점근적 정규성 가정에 의존하지 않는 “정확한” 사후 분포를 사용하여 결과를 생성합니다. 이는 모형의 모수에 대한 사전정보를 통합하기 때문에 소규모 시계열 자료에서도 매우 안정적인 추정치를 제공합니다.
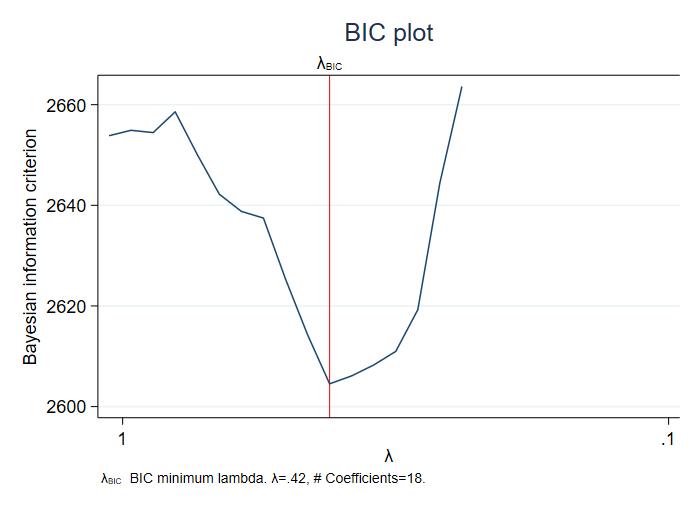
패널티 모수의 선택은 라쏘분석의 기초입니다. 작은 패널티의 사용은 너무 많은 변수를 포함시킬 수 있고 큰 패널티는 잠재적으로 중요한 변수를 너무 많이 누락시킬 수도 있습니다. 이미 Stata에서는 패널티 선택방법으로 라쏘 추정 시 교차-검증, 적응, 플러그인 방법을 제공하고 있습니다. 사용자는 이제 베이지안 정보기준(Bayesian information criterion, BIC)를 패널티 모수로 사용할 수 있습니다. 예측을 위한 라쏘 모형과 추론을 위한 라쏘 모형에서 selection(bic) 옵션을 추가하면 패널티 모수 선택방법으로 BIC가 적용됩니다. 또한 새로운 사후추정명령어인 bicplot은 패널티 모수의 변화에 따른 BIC 값들을 그래프로 표현하여 BIC 값을 최소화하는 패널티 모수의 값을 시각적으로 쉽게 확인할 수 있습니다.
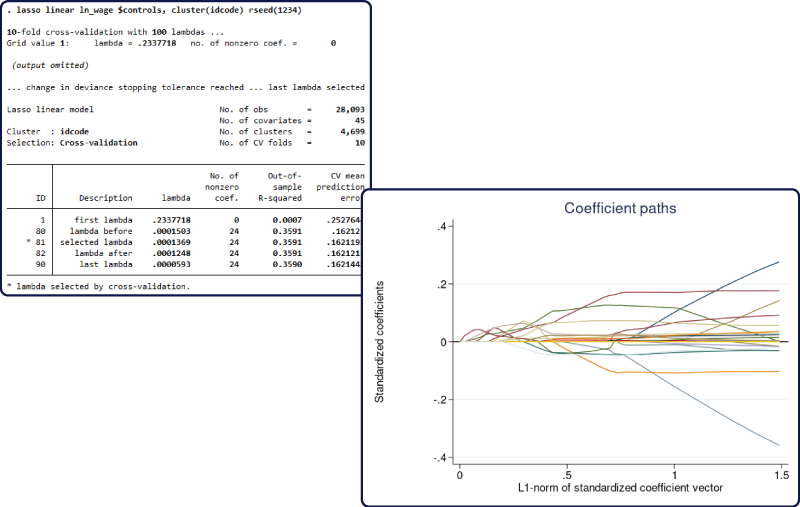
사용자는 이제 라쏘분석에서 군집화 자료(clustered data)를 적절하게 분석할 수 있습니다. 자료의 군집화 구조를 무시하는 것은 동일그룹 내 관측치간 상관으로 인해 적절하지 않은 결과를 도출할 수 있습니다. lasso와 elasticnet과 같은 예측을 위한 라쏘 명령어에서, 사용자는 새롭게 추가된 vce(cluster clustvar) 옵션을 적용할 수 있습니다. poregress와 같은 추론을 위한 라쏘 명령어에서도 동일하게 사용자는 새롭게 추가된 vce(cluster clustvar) 옵션을 적용할 수 있습니다.

사용자는 이제 dsge와 dsgenl 명령어에 bayes: 접두명령어를 추가하여 베이지안 선형/비선형 동태확률 일반균형(DSGE) 모형을 추정할 수 있습니다. 베이지안 모형에서는 30개 이상의 서로 다른 사전분포 중 선택된 분포에 의해 모형 모수들의 범위에 대한 정보를 통합합니다. 또한 베이지안 IRF 분석, 구간가설검정, 모형비교를 위한 베이즈 요인계산 등을 지원합니다.
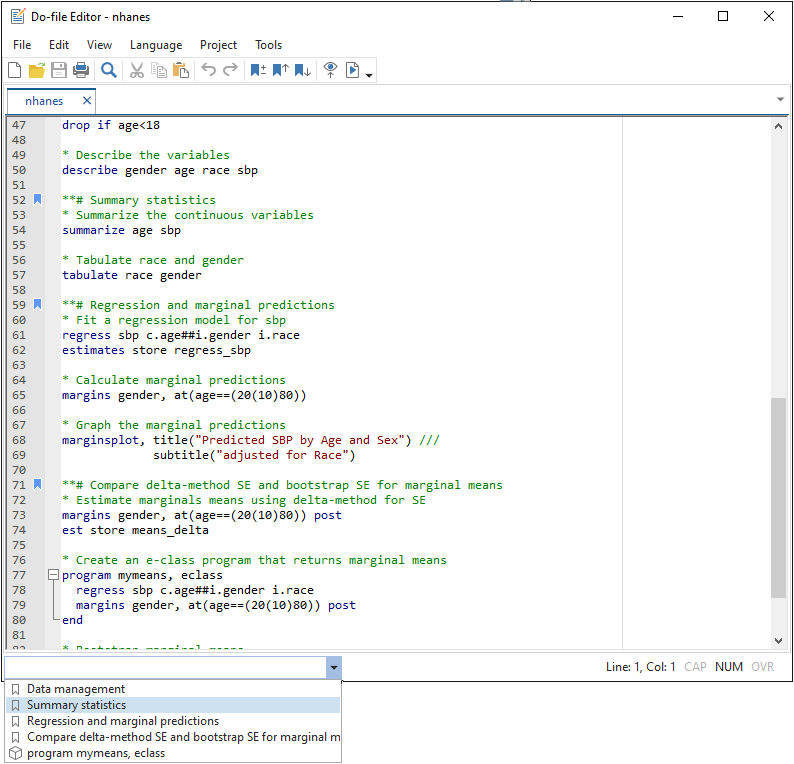
Stata 17의 Do-file 편집기는 아래 내용의 개선사항이 있습니다. 1. 북마크: do-files에 북마크 저장 2. 새로운 탐색기능: do 파일을 쉽게 탐색 3. Syntax 하이라이트가 이제 Java와 XML 지원 4. 선택한 영역의 인용부호, 괄호 자동완성 북마크: Do-파일편집기의 기능개선과 관련하여, 많은 요청사항 중 하나는 do 파일에 북마크를 저장하는 것이었습니다. 북마크는 나중에 편집줄에 표시를 남겨 나중에 쉽게 찾기 위해 사용됩니다. 북마크는 특히 매우 긴 do파일에서 유용합니다. 사용자는 do파일 내 자료관리, 기초 통계량 출력, 통계적 분석과 같은 각 영역에 북마크를 추가할 수 있습니다. 그리고 사용자는 메뉴나 도구상자 혹은 새로운 탐색창을 통해 각 영역을 스크롤없이 찾고자 하는 위치로 빠르게 이동할 수 있습니다. 탐색기능: Stata 17은 북마크 목록이나 라벨을 보여주는 새로운 탐색기능을 통해 do파일을 쉽게 탐색할 수 있습니다. Do-파일편집기에서 탐색창의 북마크를 선택하면 북마크가 된 줄로 이동합니다. 북마크 기능향상과 함께 탐색창은 do 파일 내의 프로그램 목록을 보여줍니다. 탐색창에서 프로그램을 선택하면 프로그램 정의가 있는 곳으로 이동하게 됩니다. 프로그램 위치를 탐색창에 추가하는 것은 어떠한 노력도 필요하지 않습니다. Do-파일편집기는 자동적으로 인식하여 프로그램 정의가 있는 위치는 탐색창에 추가해 줄 것입니다.

Stata 17은 Stata와 Mata에서 날짜 및 시간을 편하게 다루기 위한 새로운 기능을 추가하였습니다. 새로운 기능은 세가지 범주로 요약할 수 있습니다. 1. 날짜시간 기간: 연령과 같은 기간을 계산하기 위해 설계된 기능 2. 상대 날짜: 특정한 날짜를 기준으로 상대적인 기간을 계산하는 기능 3. 날짜시간 구성요소: 날짜시간 값으로부터 개별적인 구성요소를 추출하는 기능 새로운 기능은 윤년, 윤일, 윤초 계산을 포함합니다. 윤초는 협정 세계시(UTC)에서 오차를 보정하기 위해 적용되는 1초입니다.
Stata 17은 호환 하드웨어(모든 인텔 및 AMD 기반 64bit 컴퓨터)에서 최적화된 LAPACK 루틴을 지원하는 인텔 수학커널라이브러리 (MKL)를 소개합니다. LAPACK은 선형대수패키지(Linear Algebra PACKage)의 약자로 연립방정식, 고유값 계산, 특이값 분해 등과 같은 수치계산을 위한 라이브러리입니다. Mata 연산자와 함수(예를 들어 qrd( ), lud( ), cholesky( ))는 LAPACK의 이점을 활용하여 많은 수치연산을 수행합니다. 최신 인텔 및 AMD 프로세서에서 사용된 64-bit 인텔 x86-64 명령어세트는 매우 최적화된 최신의 MKL LAPACK 루틴을 제공합니다. MKL을 사용한 Mata 함수와 연산자는 성능에 있어서 매우 큰 이점을 가집니다. 여기서 매우 중요한 점은 사용자가 성능을 향상시키기 위해 어떠한 작업도 할 필요가 없다는 것입니다. 호환가능한 하드웨어 환경에서 Mata 함수 및 연산자를 사용하는 Stata 명령어와 Mata 함수 및 연산자는 인텔 MKL을 자동적으로 사용할 것입니다.
Mac 용 Stata 17은 유니버셜 어플리케이션으로 개발되어, Apple Silicon Mac과 Intel 프로세서 Mac 모두에서 네이티브 동작을 지원합니다. Apple Silicon Mac은 M1 프로세서를 탑재한 신형 맥북에어, 맥북프로 그리고 맥 미니입니다. M1 칩은 더 향상된 성능과 더 좋은 전력효율을 가지고 있습니다. 이는 M1 Mac을 사용하는 Mac 용 Stata 사용자들에게 주목할 만한 점입니다. 최근에 출시한 Apple Silicon Mac이 M1칩을 장착한 첫번째 Mac 임에도 불구하고, M1 Mac과 Intel Mac에서의 Stata 성능을 비교하면, M1 Mac이 30~35%의 성능 향상을 보였습니다. 심지어 M1 Mac과 가격이 두배 이상인 Intel Mac과 비교했을 때, M1 Mac에서 Stata 더 좋은 성능을 보이거나 동일한 성능을 보였습니다. 그리고 Apple Silicon Mac에서 오직 Apple-Silicon 네이티브 소프트웨어만 구동하고자 하는 사용자는 Stata 17의 설치부터 실행까지 어느 한부분도 Rosetta 2를 요구하지 않는 다는 점에 즐거워할 것입니다. Stata의 기능은 M1 Mac, Intel Mac 관계없이 동일하게 작동하며, M1 Mac에서의 사용을 위한 추가적인 라이선스를 요구하지 않습니다. 또한 Intel Mac 사용자를 위해, 추후 새로운 Stata 버전의 지원과 배포는 Intel Mac에서도 앞으로 몇년동안 계속될 것입니다.
Stata와 데이터 베이스 간 연결이 더 쉬워졌습니다. Stata 17에서 JDBC (Java Database Connectivity) 지원이 추가되었습니다. JDBC는 프로그램과 데이터베이스 사이에 자료를 교환하기 위한 크로스-플랫폼 표준입니다. 새로운 jdbc 명령어는 관계형 데이터베이스 혹은 비관계형 데이터베이스 관리 시스템과 자료를 교환하는 JDBC 표준을 지원합니다. 사용자는 Oracle, MySQL, Amazon Redshift, Snowflake, Microsoft SQL Server 등과 같은 매우 유명한 데이터 베이스로부터 자료를 불러들일 수 있습니다. jdbc 명령어가 좋은 점은 크로스-플랫폼 솔루션이라는 점입니다. 그렇기 때문에 JDBC 설정은 Windows, Mac, Unix 시스템에서 동일하게 동작합니다. 만약 사용자의 데이터 베이스가 JDBC 드라이버를 지원한다면, 사용자는 드라이버를 다운 받고 설치하기만 하면 jdbc 명령어를 통해 사용자 데이터베이스에 직접 자료를 읽고 자료를 쓰고 쿼리를 실행할 수 있습니다. 사용자는 전체 데이터 베이스 테이블을 Stata로 불러들이거나 SQL SELECT를 통해 테이블의 특정한 컬럼만 Stata로 불러들일 수 있습니다. 또한 사용자는 모든 변수를 데이터베이스 테이블에 삽입하거나 자료의 일부를 삽입할 수도 있습니다.
Stata17에서 사용자는 이제 Stata 내에서 Java 코드를 직접 수행하거나 포함할 수 있습니다. 사용자는 이전버전에서도 자바로 개발된 플러그인을 만들거나 사용할 수 있었습니다. 그러나 이를 위해서는 코드를 컴파일하거나 묶음 파일인 Jar형식으로 변환해야 합니다. do파일 내에서 자바의 실행은 Stata코드와 묶여서 연동되는 자바 코드 실행과 같은 유연성을 가져다 줄 것입니다. 이제 사용자는 do파일과 ado파일 안에 자바 코드를 포함할 수 있으며, 심지어 Stata내에서 JShell과 같은 자바 인터렉티브 환경을 제공합니다. 자바의 강점중 하나는 자바 가상머신과 함께 매우 광범위한 API를 포함하고 있다는 점입니다. 또한 매우 유용한 써드-파티 라이브러리를 사용할 수 있습니다. 사용자가 무엇을 필요로 하는지에 달려있지만, 사용자가 심지어는 다수의 코어가 가지는 장점을 활용하기위해 병렬화된 코드를 구성할 수도 있습니다. 사용자가 작성한 자바 코드는 즉시 컴파일 되기 때문에 외부 컴파일러를 필요로 하지 않습니다! 추가적으로, Stata와 Java 사이의 연동을 제공하는 Stata 기능 인터페이스(Stata Function Interface, SFI) 자바 패키지를 포함하고 있습니다. SFI 패키지는 Stata의 현재 자료, 프레임, 매크로, 스칼라, 매트릭스, 값 라벨, 특성, 전역 Mata 매트릭스, 날짜 및 시간 값 등을 접근하게 하는 클래스입니다. Stata 설치와 동시에 자바개발자키트(Java Development Kit, JDK)도 함께 설치되어, Java 사용을 위한 추가적인 설정을 할 필요가 없습니다.
Stata 17에서 우리는 H2O와의 연결을 시도하였습니다. H2O는 스케일러블하고 분산된 오픈소스 머신러닝 및 예측분석 플랫폼입니다. (https://docs.h2o.ai) H20와의 통합을 통해, 사용자는 Stata에서 H20 클러스터를 시작하고, 연결하고, 쿼리를 요청할 수 있습니다. 추가적으로 우리는 클러스터에서 자료(H2O 프레임)를 수정하도록 하는 명령어들을 제공합니다. 예를 들면, 사용자는 Stata에서 불러들인 현재 자료를 H20 프레임으로 생성할 수 있습니다. 그리고 Stata 안에서 H20 프레임을 분할하거나 합치거나 하는 쿼리를 요청할 수 있습니다. 이러한 작업이 아직 실험단계지만, 우리는 우리의 사용자들이 시도해볼 수 있도록 만드는 것을 목표로 하고 있습니다. 하지만, 이는 실험적인 기능이기 때문에, syntax와 기능이 추후 변경될 수도 있습니다. H2O 기능에 접근하는 Stata 명령어를 사용할 때 알아 둬야 할 점은 그 기능이 H2O의 기능이라는 점입니다. 사용자가 Stata 명령어를 통해 접근하더라도, 실제 기능 및 그 수행은 Stata외부에 있는 H2O에 달려있습니다.
우리는 PyStata라고 부르는 새로운 개념을 Stata 17에서 소개합니다. PyStata는 Stata와 Python 간 상호작용하는 모든 방식을 포함하는 용어입니다. Stata16은 Stata 내에서 Python 코드를 실행하는 기능을 포함하고 있었습니다. Stata 17에서는 새로운 pystata 파이썬 패키지를 통해 독립적인 파이썬 환경에서 Stata를 동작할 수 있도록 기능을 확장하였습니다. 사용자는 IPython 커널기반 환경(예를 들어, jupyter Notebook 및 콘솔, Jupyter Lab 및 콘솔)에서 편리하게 Stata와 Mata에 접근할 수 있습니다; 혹은 명령어 줄로 Python을 접근하는 환경(예를 들어, 윈도우 명령 프롬프트, macOS 터미널, Unix 터미널, Python 통합개발환경)에서도 가능합니다.
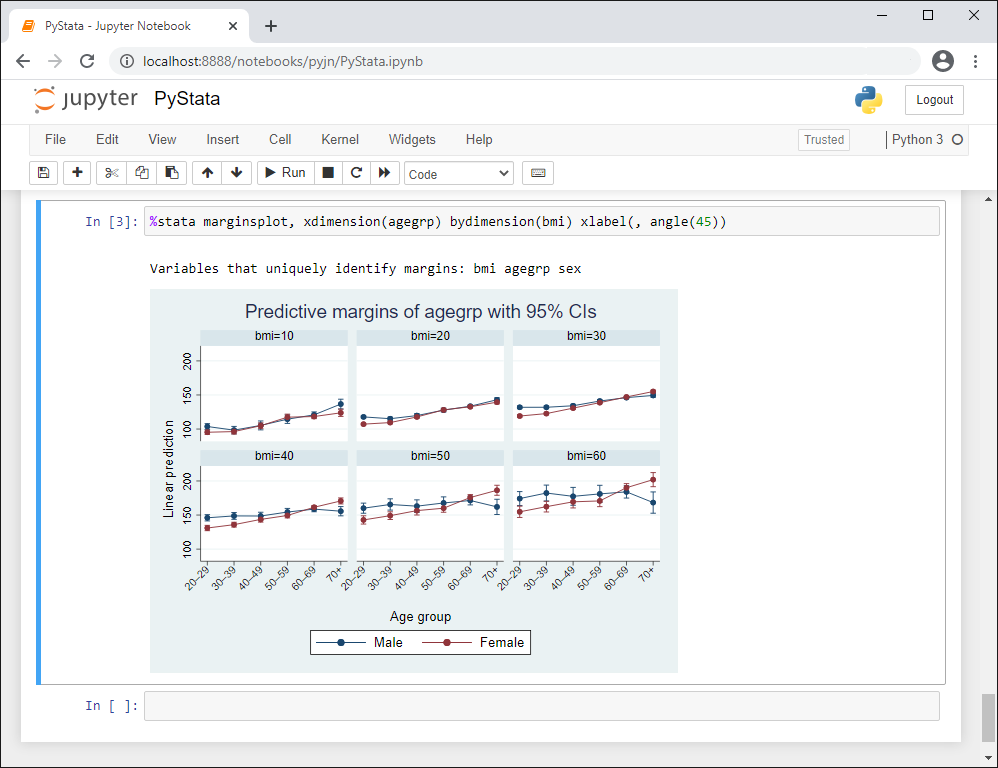
Jupyter Notebook은 상호작용 컴퓨팅 및 개발을 위한 강력하고 사용하기 쉬운 웹기반 어플리케이션입니다. Jupyter notebook은 실행코드 및 결과, 시각화, 방정식 및 수식, 설명 텍스트, 그리고 풍부한 미디어를 한개의 notebook 문서로 구성할 수 있습니다. 이러한 장점으로 인해 연구자들과 과학자들은 그들의 생각과 협업 및 혁신의 결과를 공유하기위한 도구로 많이 사용되고 있습니다. Stata 17부터 PyStat 내 한 부분으로 사용자는 IPython (interactive Python) 커널을 통해 Jupyter Notebook에서 Stata와 Mata를 수행할 수 있습니다. 이는 Python과 Stata의 장점을 조합한 단일 환경을 통해 사용자의 작업을 쉽게 재현가능하고 다른 사람과 공유가 가능하게 만들어 준다는 의미입니다. Jupyter notebook 내 Stata 지원은 새로운 Python 패키지인 pystata를 통해 구동됩니다.